
Comments
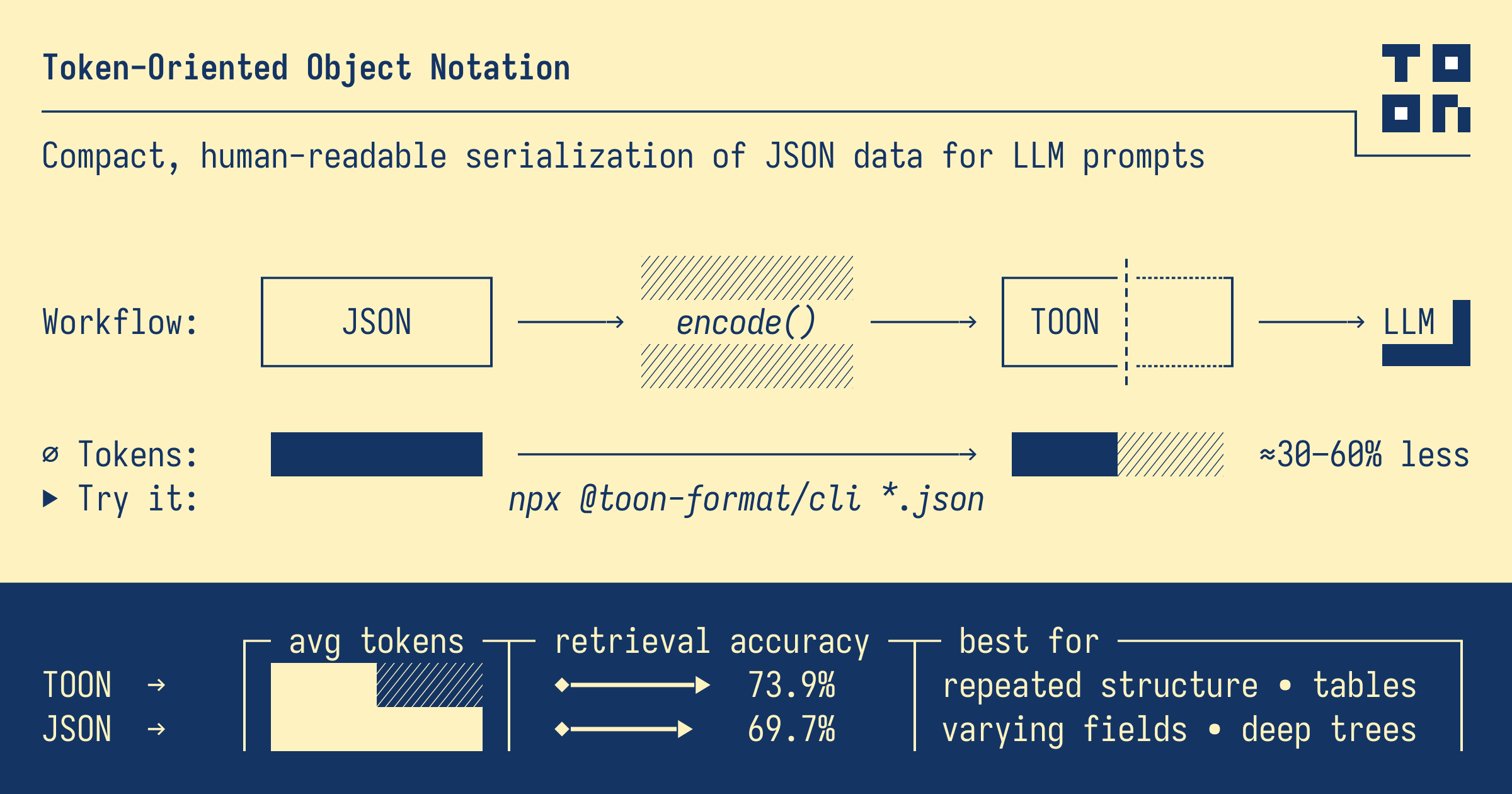
Token-Oriented Object Notation is a compact, human-readable format designed for passing structured data to Large Language Models with significantly reduced token usage.
TOON excels at uniform complex objects – multiple fields per row, same structure across items. It borrows YAML's indentation-based structure for nested objects and CSV's tabular format for uniform data rows, then optimizes both for token efficiency in LLM contexts.
AI is becoming cheaper and more accessible, but larger context windows allow for larger data inputs as well. LLM tokens still cost money – and standard JSON is verbose and token-expensive:
TOON conveys the same information with fewer tokens:
Format familiarity matters as much as token count.
CSV: best for uniform tables. JSON: best for non-uniform data. TOON: best for uniform complex (but not deeply nested) objects.
TOON switches to list format for non-uniform arrays. In those cases, JSON can be cheaper at scale.
💸 Token-efficient: typically 30–60% fewer tokens than JSON 🤿 LLM-friendly guardrails: explicit lengths and field lists help models validate output 🍱 Minimal syntax: removes redundant punctuation (braces, brackets, most quotes) 📐 Indentation-based structure: replaces braces with whitespace for better readability 🧺 Tabular arrays: declare keys once, then stream rows without repetition
Tested across 3 LLMs with data retrieval tasks:
Advantage: TOON achieves 86.6% accuracy (vs JSON's 83.2%) while using 46.3% fewer tokens.
TOON formatting is deterministic and minimal:
Indentation: 2 spaces per nesting level.
key: value for primitives (single space after colon). key: for nested/empty objects (no trailing space on that line).
Delimiter encoding: Comma delimiters are implicit in array headers (e.g., tags[3]:, items[2]{id,name}:). Tab and pipe delimiters are explicitly shown in array headers (e.g., tags[3|]:, items[2 ]{id name}:). Primitive arrays inline: key[N]: v1,v2 (comma) or key[N]: v1v2 (tab/pipe). Tabular arrays: key[N]{f1,f2}: … (comma) or key[N]{f1f2}: … (tab/pipe). List items: two spaces, hyphen, space (" - …").
Whitespace invariants:
No trailing spaces at end of any line. No trailing newline at end of output.
Simple objects with primitive values:
Nested objects:
When all objects share the same primitive fields, TOON uses an efficient tabular format:
Tabular formatting applies recursively: nested arrays of objects (whether as object properties or inside list items) also use tabular format if they meet the same requirements.
Arrays that don't meet the tabular requirements use list format:
When objects appear in list format, the first field is placed on the hyphen line:
When you have arrays containing primitive inner arrays:
Empty containers have special representations:
TOON quotes strings only when necessary to maximize token efficiency. Inner spaces are allowed; leading or trailing spaces force quotes. Unicode and emoji are safe unquoted.
Keys are quoted when any of the following is true:
Quotes and control characters in keys are escaped (e.g., "he said \"hi\"", "line\nbreak").
String values are quoted when any of the following is true:
For arrays of objects to use the efficient tabular format, all of the following must be true:
If any condition fails, TOON falls back to list format.
Some non-JSON types are automatically normalized for LLM-safe output:
Number normalization examples:
Converts any JSON-serializable value to TOON format.
Parameters:
value – Any JSON-serializable value (object, array, primitive, or nested structure). Non-JSON-serializable values (functions, symbols, undefined, non-finite numbers) are converted to null. Dates are converted to ISO strings, and BigInts are emitted as decimal integers (no quotes). options – Optional encoding options:
indent?: number – Number of spaces per indentation level (default: 2) delimiter?: ',' | '\t' | '|' – Delimiter for array values and tabular rows (default: ',') lengthMarker?: '#' | false – Optional marker to prefix array lengths (default: false)
A TOON-formatted string with no trailing newline or spaces.
The delimiter option allows you to choose between comma (default), tab, or pipe delimiters for array values and tabular rows. Alternative delimiters can provide additional token savings in specific contexts.
Using tab delimiters instead of commas can reduce token count further, especially for tabular data:
Tabs are single characters and often tokenize more efficiently than commas. Tabs rarely appear in natural text, reducing the need for quote-escaping. The delimiter is explicitly encoded in the array header, making it self-descriptive.
Considerations:
Some terminals and editors may collapse or expand tabs visually. String values containing tabs will still require quoting.
Pipe delimiters offer a middle ground between commas and tabs:
The lengthMarker option adds an optional hash (#) prefix to array lengths to emphasize that the bracketed value represents a count, not an index:
TOON works best when you show the format instead of describing it. The structure is self-documenting – models parse it naturally once they see the pattern.
Wrap your encoded data in a fenced code block (label it ```toon for clarity). The indentation and headers are usually enough – models treat it like familiar YAML or CSV. The explicit length markers ([N]) and field headers ({field1,field2}) help the model track structure, especially for large tables.
For output, be more explicit. When you want the model to generate TOON:
Show the expected header (users[N]{id,name,role}:). The model fills rows instead of repeating keys, reducing generation errors. State the rules: 2-space indent, no trailing spaces, [N] matches row count.
Here's a prompt that works for both reading and generating:
Token counts vary by tokenizer and model. Benchmarks use a GPT-style tokenizer (cl100k/o200k); actual savings will differ with other models (e.g., SentencePiece). TOON is designed for LLM contexts where human readability and token efficiency matter. It's not a drop-in replacement for JSON in APIs or storage. Tabular arrays require all objects to have exactly the same keys with primitive values only. Arrays with mixed types (primitives + objects/arrays), non-uniform objects, or nested structures will use a more verbose list format. Object key order is preserved from the input. In tabular arrays, header order follows the first object's keys. Arrays mixing primitives and objects/arrays always use list form:
- [2]: 1,2
Deterministic formatting: 2-space indentation, stable key order, no trailing spaces/newline.